Manuscripts
शोध्य-प्राचीन-ग्रन्थ-कोषः
Online Repository of Content-searchable Ancient Indic ManuscriptsIntroduction
To dramatically accelerate the deciphering of Bharat’s millions of handwritten manuscripts from ancient scripts with human-assisted AI, SKF has developed a crowd-sourced OCR editor and OCR trainer facility. This is a truly multi-institutional collaboration and testament to the versatility of siddhantakosha.org’s e-Bhashya architecture.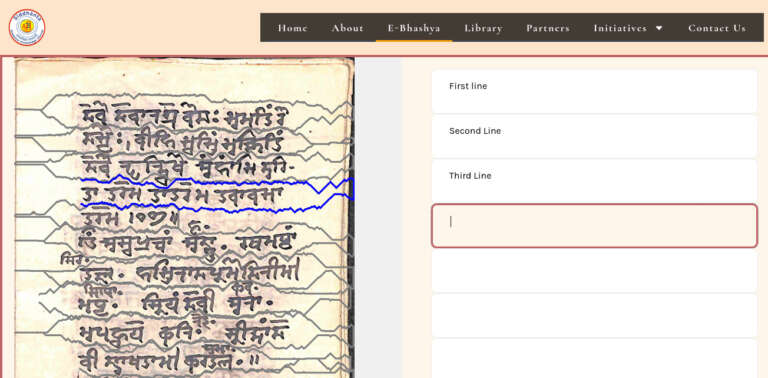
Objective
Our first objective is to deploy a publicly accessible online repository of digitized Ancient Manuscripts of Bharat across multiple Indian languages and scripts, that is fully searchable by content, with an AI bot interface. Our second objective is to assist others in similarly transforming their manuscript collections. A searchable repository of that scale is not available today due to lack of requisite tools and technologies as well as a coherent software architecture to glue them together.Background
Bharat is known to have more than 3 crore manuscripts in multiple languages and archaic scripts spread across the country. The National Mission for Manuscripts has digitally scanned much of this collection. However that collection is not available in a form searchable by content. As a result, it is not efficiently utilizable, nor its content known. There are multiple technical reasons for this. Almost all of these manuscripts are handwritten text in ancient scripts for which text extraction software (called Optical Character Recognition or OCR) doesn’t exist. The sheer scale of the content is so overwhelming that it cannot be addressed in reasonable time without automation. In order to bootstrap the development of such software using AI, we need authentic training data supplied manually by human experts who can decipher the ancient scripts. Next, we need to develop software that gets trained on that data and applies it on a large corpus of scanned manuscript content, and indexes it for search.Approach
The initial goal of this project is to develop the crucial bootstrapping training data for at least 2 lakh lines of manuscript text (10000 pages x 20 lines/page) in 5 dominant ancient Indic scripts via employing distributed teams of human experts. Once enough training data is ready, we can leverage AI experts in-house as well as at other organizations to develop tools to dramatically accelerate and scale the text extraction to millions of pages. The diagram below depicts in summary the planned overall workflow.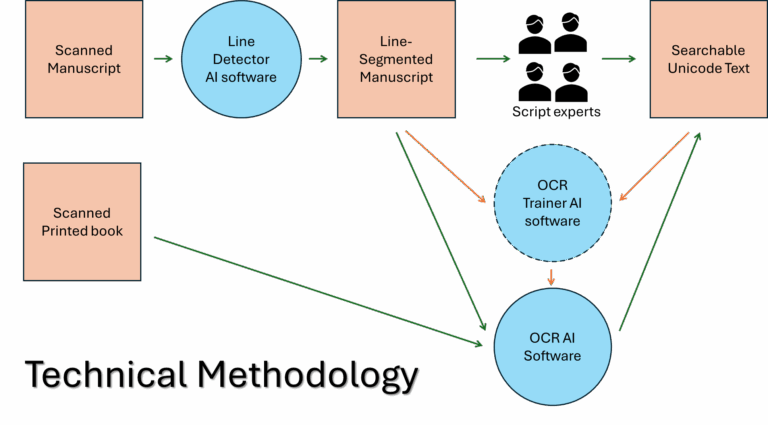
SKF offers RESTful API-based access to this corpus as images of line segments with their corresponding Unicode text. OCR training and text conversion workflows can be built on top. SKF’s software architecture also allows third-party OCR tools to be incorporated into its platform for application on large collections of scanned manuscripts. It has already integrated Google’s OCR API that way and made a million pages of Indic printed books searchable.
The Larger Vision
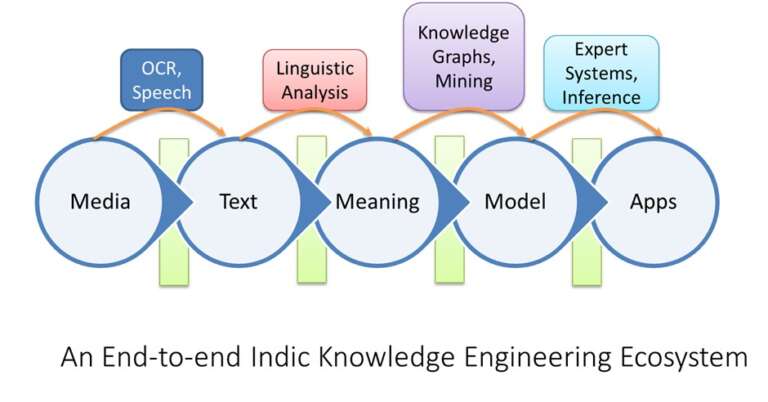
Making manuscripts searchable is only the first step of our larger vision to make Bharatiya knowledge deployable by transforming textual knowledge into consultable scientific models in various disciplines of interest. SKF’s e-Bhashya software architecture provides an open, API-driven extensible infrastructure for this purpose. At its core is a new markup language called IKML designed for flexible knowledge representation. A research paper published at World Sanskrit Conference 2025 describes this architecture in detail.
SKF intends to create Shaastra-based scientific models to unleash the full power of Bharatiya knowledge embedded in its literature. We see scalable deciphering of manuscripts as an important initial step in that direction.
| Title | Link | Script |
|---|---|---|
| Gayatri Vyahriti Sharada Manuscript – Toshkhani Collection | Edit OCR | Sharada |
| Jaiminiya Sutra with Artha Sangraha Comm_Mss No 71_Sharada_Alm 1 – Panjab Uni | Edit OCR | Sharada |
| Siva Sutra Tika Water Damage – Devanagari Manuscript | Edit OCR | Devanagari |
| Katha Sarit Sagar Hindi Translation 1866 Manuscript KRI-50 – Pandit Krishna | Edit OCR | Devanagari |
| Shiva Rahasya Part 7 Second Half Tamil Manuscript – Jangamwadi Math Collection | Edit OCR | Tamil |
| Vira Shaivachara Kaustubha Kriya Kand by Maunappa Kannada Manuscript – Jangamwadi Math Collection | Edit OCR | Kannada |
| KRI-115_Maha Gayatri Mantra Vyakhyanam of Maha Maheshwar Shivopadhyaya – Devanagari Manuscript at KRI | Edit OCR | Devanagari |
| Tantra Vartikam_5366_Alm_24_Shlf_3_Telugu – Mimansa | Edit OCR | Telugu |